
ANT: Augment And Think 🐜
Published:
Task: Answer questions of various forms (MCQ, open-ended, correctly-led and wrongly-led) about short-form videos.
Result:
Correctness Score: 58.07% (ANT), 45.2% (GPT4o)
Robustness Score: 15.3% (ANT), 8% (GPT4o)
Core Ideas:
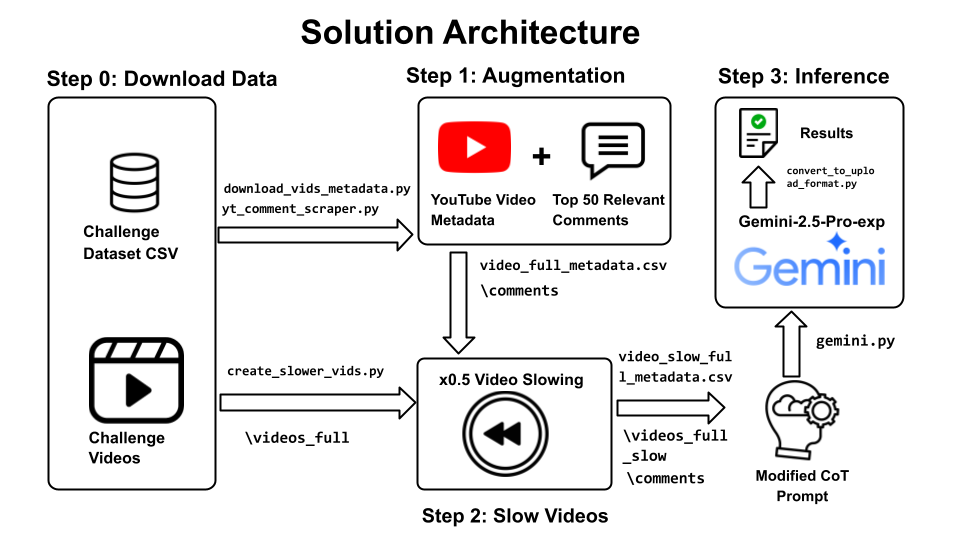
- Rich Context Augmentation: We gather extensive metadata associated with each YouTube video, including title, description, channel information, keywords, captions (transcripts), and critically, user comments. Comments often contain discussions, clarifications, or reveal audience perception, which can be vital clues (e.g., users pointing out a video is reversed).
- Video Pre-processing (Slowing Down): Recognising that models like Google Gemini process video at a fixed rate (e.g., 1 frame per second), we slow down the input videos (to 0.5x speed). Our intuition is that this allows the model to observe finer-grained temporal details within its fixed sampling rate, potentially making subtle motion patterns (like unnatural reversals) more apparent.
- Structured Prompt Engineering: We use Google’s Gemini Pro 2.5 model with a carefully crafted prompt (
v3). This prompt explicitly asks the model to:- Describe the video’s start, middle, and end segments.
- Detail its reasoning process step-by-step (
THINKING STEPS). - Provide a final answer (
FINAL ANSWER). This structured approach encourages more thorough analysis before committing to an answer and leverages the rich context gathered in the previous steps.